周二组会汇报:Phase-2 SFT 实验结果
- 生成时间: 2026-05-12 05:27:09
- 数据来源:
eval_outputs/*/metrics.json
- 表格列说明:
Top1 = top1_accuracy_single_label(单标签样本上预测命中率);Macro-F1 = 各动作类别 F1 的简单平均,反映长尾类别表现。
- 数值单位: 百分比。
- 备注: 为满足只保留指定列的要求,对比实验条件写在
Model 后的括号中。
- 关于指标选择: 当前评测样本几乎都是单标签、模型也只输出一个动作,因此样本级
precision/recall/F1 在数学上会退化为 Top1(已核验:eval_sft.py::compute_metrics 计算无误,是单标签 + 单预测下的必然结果),所以这里改用 Macro-F1 作为第二列指标。
名词解释
- Phase-1 / 新 Phase-1 (
newp1): Phase-1 是冻结 DINOv2 视频编码器之上的三分支对比预训练模块(行为 token、物种、环境)。newp1 指改用在 三个数据集上联合对比预训练得到的新 Phase-1 权重 ./checkpoints_contrastive_three_datasets/best.pt (epoch 15),相比早期单数据集 Phase-1 有更稳定的视觉表示。
- Phase-2 / SFT: 在冻结 Phase-1 + 冻结 LLM 的基础上,训练 Q-former、可选的 cls 头与 LoRA,做候选动作多选任务的有监督微调。
- M (
num_qformer_queries): Q-former 可学习 query 数,控制送入 LLM 的视觉 token 数量(M ∈ {32, 64, 128, 512})。
- answer_order:
actions_first: 模型先输出 <predicted_actions>...</predicted_actions>,再写分析。analysis_first: 先写一段分析,再输出 <predicted_actions>...</predicted_actions>,相当于让 LLM "先思考再答题"。- 标签简化 (
_simple, newp1_simple): 把数据集里冗长 / CamelCase 的官方动作标签改写成简短的日常英文词,再喂给 LLM 当候选池和监督答案。Phase-2 训练和评测使用同一份映射 (label_mappings/lote_simple.json、label_mappings/mammalnet_simple.json)。
- 辅助分类头 (
cls): 在 Phase-2 中为 Q-former 输出加一个多标签 BCE 分类头 (use_cls_head),与 LM loss 联合训练 (λ=0.1),作为额外监督信号;推理时仍用 LM 的文本生成作为预测,分类头只在训练时起作用。
p1-own: Phase-2 训练用该数据集自身单独的 Phase-1 contrastive 权重(而不是三数据集联合 Phase-1)。e2-drop10: Phase-2 训练时第 2 个 epoch 起对 Q-former 输入加 10% dropout 的正则变体。flip-balanced: 训练数据按类别做 flip / 平衡采样的变体。- Cross-dataset / Zero-shot: 用某个数据集训出来的 Phase-2 模型,直接在另一数据集上零样本测试(如
MammalNet→LoTE)。
标签简化举例
LoTE-Animal(21 类,原始名称 → 简化名称):
| 原始标签 |
简化标签 |
Aggregation |
grouping |
CircumanalGlandSigning |
scent marking |
DrinkWater |
drinking |
Defecating |
pooping |
Exploratory |
exploring |
Feeding |
eating |
Miscellaneous |
other |
Parental |
parenting |
Smelling |
sniffing |
Urinating |
peeing |
UrineSigning |
urine marking |
MammalNet(12 类,原始名称 → 简化名称):
| 原始标签 |
简化标签 |
drinks water |
drinking |
eats food |
eating |
fights against other animals |
fighting |
gives birth to a baby |
birthing |
grooms/cleans itself or other animal |
grooming |
hunts other animals |
hunting |
mates with other animals |
mating |
nurses or breastfeeds its baby |
nursing |
为什么这样做有效: 简化后的标签更接近 LLM 预训练分布的常用日常动词,候选池中的 token 也更短,使得 LLM 在多选生成时更容易给出正确动作;从下面的对比表可以看到,标签简化在两个数据集 + 两个 LLM 上都带来稳定且显著的提升。
1. 标签简化对比(actions_first, M=64)
| Model |
数据集 |
M |
Top1 |
Macro-F1 |
| Qwen2.5-7B(无标签简化) |
LoTE-Animal |
64 |
42.81 |
14.99 |
| Qwen2.5-7B(有标签简化) |
LoTE-Animal |
64 |
59.60 |
29.10 |
| Qwen3-8B(无标签简化) |
LoTE-Animal |
64 |
32.51 |
6.82 |
| Qwen3-8B(有标签简化) |
LoTE-Animal |
64 |
63.37 |
27.35 |
| Qwen2.5-7B(无标签简化) |
MammalNet |
64 |
47.22 |
35.18 |
| Qwen2.5-7B(有标签简化) |
MammalNet |
64 |
70.23 |
62.19 |
| Qwen3-8B(无标签简化) |
MammalNet |
64 |
53.12 |
42.04 |
| Qwen3-8B(有标签简化) |
MammalNet |
64 |
69.23 |
60.41 |
2. NewP1 + 标签简化:analysis_first
| Model |
数据集 |
M |
Top1 |
Macro-F1 |
| Qwen2.5-7B |
LoTE-Animal |
64 |
68.49 |
33.97 |
| Qwen2.5-7B |
LoTE-Animal |
128 |
68.54 |
35.95 |
| Qwen2.5-7B |
LoTE-Animal |
512 |
67.34 |
33.36 |
| Qwen3-8B |
LoTE-Animal |
64 |
66.73 |
36.34 |
| Qwen3-8B |
LoTE-Animal |
128 |
67.34 |
34.17 |
| Qwen3-8B |
LoTE-Animal |
512 |
68.14 |
34.69 |
| Qwen2.5-7B |
MammalNet |
64 |
70.45 |
60.92 |
| Qwen2.5-7B |
MammalNet |
128 |
69.93 |
59.72 |
| Qwen2.5-7B |
MammalNet |
512 |
68.68 |
58.05 |
| Qwen3-8B |
MammalNet |
64 |
70.14 |
61.96 |
| Qwen3-8B |
MammalNet |
128 |
70.33 |
61.17 |
| Qwen3-8B |
MammalNet |
512 |
69.87 |
60.41 |
3. NewP1 + 标签简化:actions_first
| Model |
数据集 |
M |
Top1 |
Macro-F1 |
| Qwen2.5-7B |
LoTE-Animal |
64 |
59.60 |
29.10 |
| Qwen2.5-7B |
LoTE-Animal |
128 |
49.60 |
23.70 |
| Qwen2.5-7B |
LoTE-Animal |
512 |
58.39 |
29.91 |
| Qwen3-8B |
LoTE-Animal |
64 |
63.37 |
27.35 |
| Qwen3-8B |
LoTE-Animal |
128 |
63.02 |
31.50 |
| Qwen3-8B |
LoTE-Animal |
512 |
64.72 |
30.15 |
| Qwen2.5-7B |
MammalNet |
64 |
70.23 |
62.19 |
| Qwen2.5-7B |
MammalNet |
128 |
69.29 |
58.91 |
| Qwen2.5-7B |
MammalNet |
512 |
68.71 |
60.86 |
| Qwen3-8B |
MammalNet |
64 |
69.23 |
60.41 |
| Qwen3-8B |
MammalNet |
128 |
69.78 |
59.56 |
| Qwen3-8B |
MammalNet |
512 |
69.38 |
59.19 |
4. 辅助分类头对比(actions_first, M=64)
| Model |
数据集 |
M |
Top1 |
Macro-F1 |
| Qwen2.5-7B(无辅助分类头) |
LoTE-Animal |
64 |
59.60 |
29.10 |
| Qwen2.5-7B(+辅助分类头) |
LoTE-Animal |
64 |
55.18 |
31.99 |
| Qwen2.5-7B(无辅助分类头) |
MammalNet |
64 |
70.23 |
62.19 |
| Qwen2.5-7B(+辅助分类头) |
MammalNet |
64 |
70.20 |
59.83 |
5. p1-own 变体对比(actions_first, M=64)
| Model |
数据集 |
M |
Top1 |
Macro-F1 |
| Qwen2.5-7B(baseline) |
LoTE-Animal |
64 |
59.60 |
29.10 |
| Qwen2.5-7B(p1-own) |
LoTE-Animal |
64 |
53.92 |
23.96 |
| Qwen3-8B(baseline) |
LoTE-Animal |
64 |
63.37 |
27.35 |
| Qwen3-8B(p1-own) |
LoTE-Animal |
64 |
62.11 |
28.16 |
| Qwen2.5-7B(baseline) |
MammalNet |
64 |
70.23 |
62.19 |
| Qwen2.5-7B(p1-own) |
MammalNet |
64 |
72.54 |
65.53 |
| Qwen3-8B(baseline) |
MammalNet |
64 |
69.23 |
60.41 |
| Qwen3-8B(p1-own) |
MammalNet |
64 |
70.90 |
62.24 |
6. e2-drop10 变体对比(actions_first, M=64)
| Model |
数据集 |
M |
Top1 |
Macro-F1 |
| Qwen2.5-7B(baseline) |
LoTE-Animal |
64 |
59.60 |
29.10 |
| Qwen2.5-7B(e2-drop10) |
LoTE-Animal |
64 |
60.65 |
30.35 |
| Qwen3-8B(baseline) |
LoTE-Animal |
64 |
63.37 |
27.35 |
| Qwen3-8B(e2-drop10) |
LoTE-Animal |
64 |
63.92 |
27.02 |
| Qwen2.5-7B(baseline) |
MammalNet |
64 |
70.23 |
62.19 |
| Qwen2.5-7B(e2-drop10) |
MammalNet |
64 |
69.99 |
61.53 |
| Qwen3-8B(baseline) |
MammalNet |
64 |
69.23 |
60.41 |
| Qwen3-8B(e2-drop10) |
MammalNet |
64 |
70.05 |
60.23 |
7. flip-balanced 变体对比(actions_first, M=64)
| Model |
数据集 |
M |
Top1 |
Macro-F1 |
| Qwen2.5-7B(baseline) |
LoTE-Animal |
64 |
59.60 |
29.10 |
| Qwen2.5-7B(flip-balanced) |
LoTE-Animal |
64 |
53.27 |
25.74 |
| Qwen3-8B(baseline) |
LoTE-Animal |
64 |
63.37 |
27.35 |
| Qwen3-8B(flip-balanced) |
LoTE-Animal |
64 |
46.38 |
19.11 |
| Qwen2.5-7B(baseline) |
MammalNet |
64 |
70.23 |
62.19 |
| Qwen2.5-7B(flip-balanced) |
MammalNet |
64 |
69.47 |
61.50 |
| Qwen3-8B(baseline) |
MammalNet |
64 |
69.23 |
60.41 |
| Qwen3-8B(flip-balanced) |
MammalNet |
64 |
68.84 |
60.26 |
8. Cross-dataset / Zero-shot(actions_first, M=64)
| Model |
数据集 |
M |
Top1 |
Macro-F1 |
| Qwen2.5-7B(MammalNet→LoTE) |
LoTE-Animal |
64 |
26.38 |
14.29 |
| Qwen3-8B(MammalNet→LoTE) |
LoTE-Animal |
64 |
10.75 |
9.57 |
| Qwen2.5-7B(LoTE→MammalNet) |
MammalNet |
64 |
34.42 |
20.79 |
| Qwen3-8B(LoTE→MammalNet) |
MammalNet |
64 |
38.70 |
23.91 |
为解释“M 越大反而 Top1/F1 没有继续提升”的现象,我们对 4 组 newp1_simple 训出的 best ckpt(Qwen2.5-7B / Qwen3-8B × LoTE / MammalNet)的 Q-former query_tokens 做了多样性分析,看看不同 M 下这些 query 是否真的被“用满”。所有图都是 4 个组合的平均结果,绘图脚本:plot_qformer_query_diversity.py,输出目录 qformer_diversity_analysis/。
9.1 奇异值谱(log 纵轴)
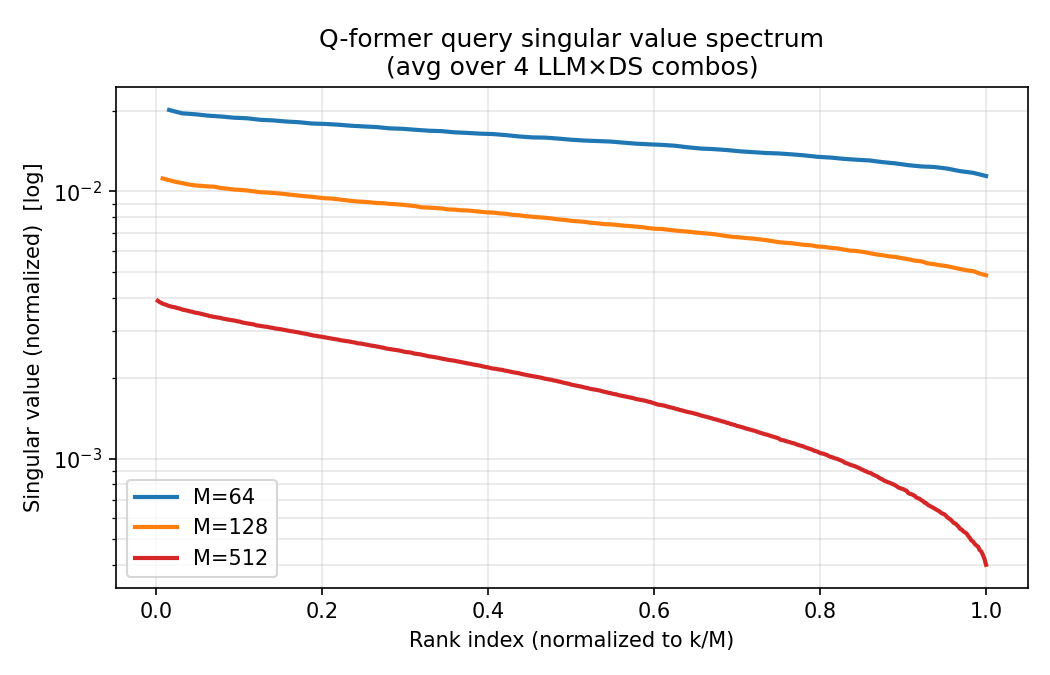
- 横轴是按 M 归一化后的 rank 序号
k/M,纵轴是归一化后的奇异值(对数刻度)。
- M=64 时谱最“平”,主奇异值占比相对均匀;
- M=128、特别是 M=512 时尾部奇异值快速衰减,意味着真正“起作用”的 query 子空间维数显著低于 M。
9.2 累积能量曲线
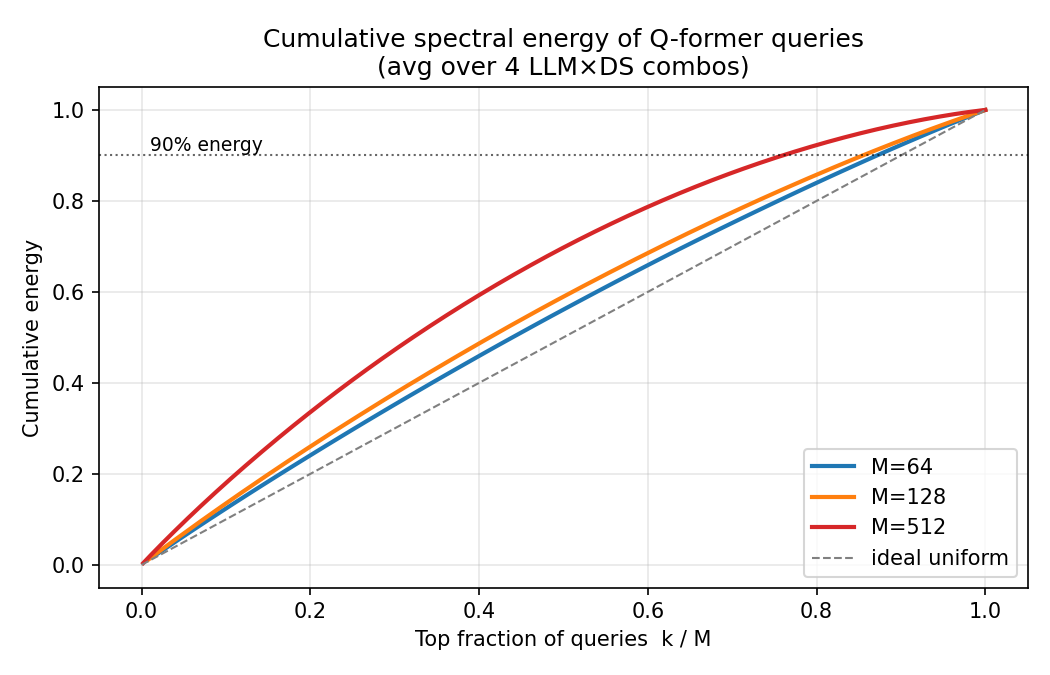
- 灰色虚线是“理想均匀”参考(每个 query 贡献相同),曲线越靠近这条线越好。
- 黑色虚线标 90% 能量阈:M=64 需要使用大约 80–85% 的 query 才能达到 90% 能量;M=512 只需要前约 40–50% 的 query,剩余一半 query 几乎贡献不到信息,是典型的 query collapse。
9.3 Pairwise abs(cosine) 分布
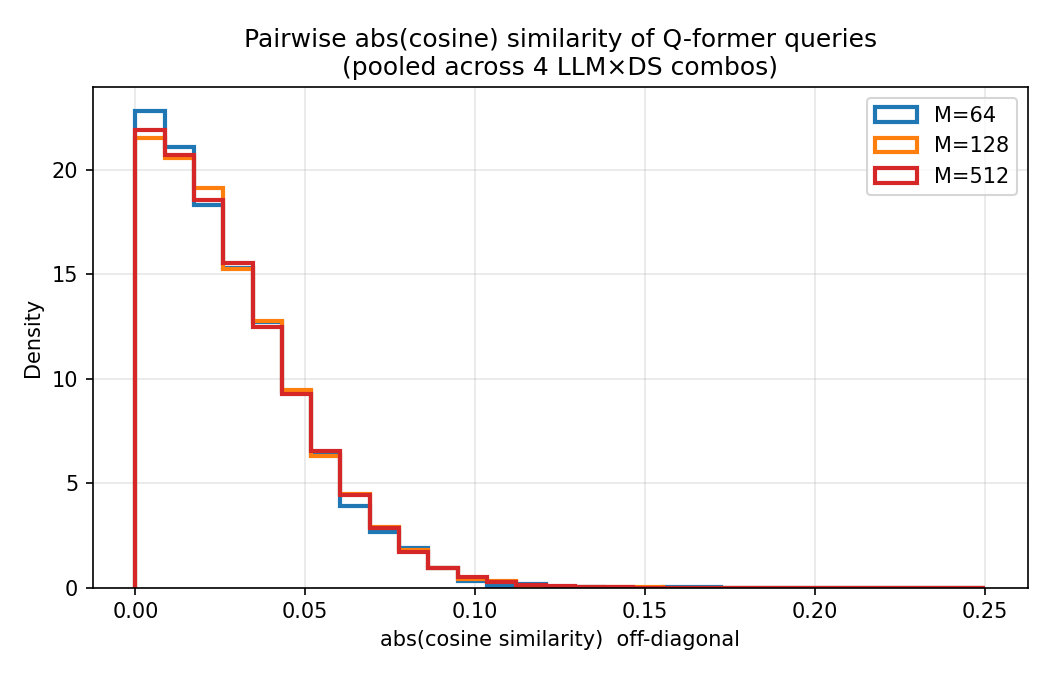
- 任意两个 query 之间归一化向量
|cos| 的密度分布;越靠近 0 表示 query 互相越正交、表征越分散。
- M=64 的分布最集中在 0 附近;M=128/512 的分布右尾更长,说明随着 M 增大,冗余、相似的 query 比例显著上升。
9.4 Effective rank 与 Gini 系数
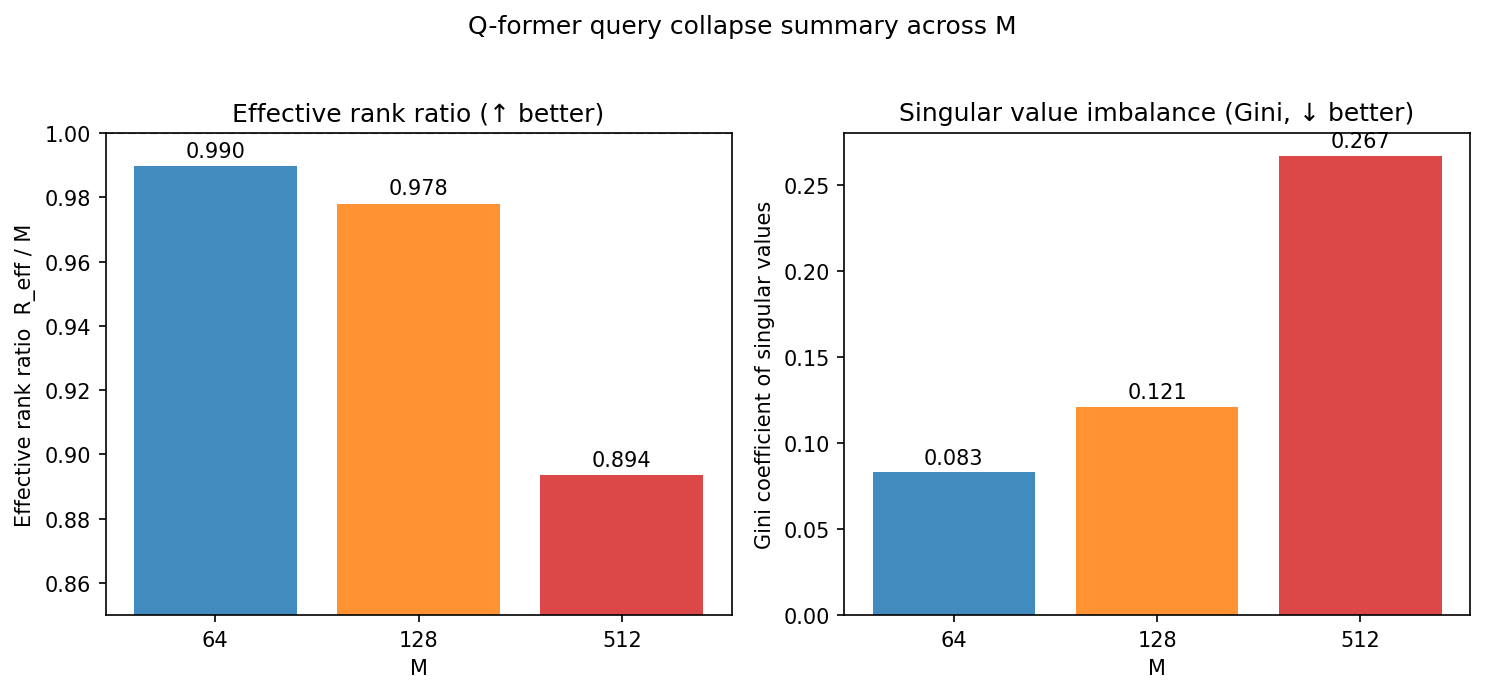
- 左图:
R_eff / M(基于谱熵的有效秩比例,越接近 1 越好)。
- 右图:奇异值的 Gini 系数(越小越平均、越大越偏斜)。
- 趋势:M 从 64 → 128 → 512,有效秩比例单调下降,Gini 单调上升,与上面三张图互相印证:增加 M 几乎只是堆叠更冗余的 query,对下游任务的增益边际递减,这也解释了 Phase-2 SFT 在 M=64 已经接近最优、M=512 反而不再提升甚至略降的现象。
10. 当前还缺 metrics 的关键实验
这些目录已有 predictions.jsonl,但还没有 metrics.json,所以未进入上面的统计表:
sft_qwen25_7b_lote_m32_newp1_simple_best_test_analysis_firstsft_qwen25_7b_mammalnet_m32_newp1_simple_best_test_analysis_firstsft_qwen3_8b_mammalnet_m32_newp1_simple_best_test_analysis_firstsft_qwen25_7b_lote_m128_newp1_simple_rankreg_best_test_analysis_firstsft_qwen3_8b_lote_m128_newp1_simple_rankreg_best_test_analysis_firstsft_qwen25_7b_mammalnet_m128_newp1_simple_rankreg_best_test_analysis_firstsft_qwen3_8b_mammalnet_m128_newp1_simple_rankreg_best_test_analysis_first